 关注寄云公众号
关注寄云公众号 
风力发电机组基于 SCADA 数据的功率曲线性能评估
问题背景
在一个风电场,往往通过 SCADA 风速和功率的散点数据来拟合实际功率曲线从而衡量风机的出力特性,一方面可以实时更新功率曲线预测未来发电量收益,另一方面能够及时发现机组运行可能存在的隐患。由于受到人为(如维修,限电等)和非人为(天气、空气密度、环境温度等)一系列因素的影响,采集到的风机功率曲线分布杂乱无序,无法直接用于机组性能分析。
 风机功率曲线散点样图
风机功率曲线散点样图
解决方案
风机功率曲线性能评估案例是首先对数据进行预处理操作,然后对数据按照风速大小进行分仓,接着采用组内方差最优算法挑选出正常的数据,再采用随机森林回归算法对筛选出的正常数据进行训练建模,最后用训练的模型计算得到该风机的标准功率曲线。
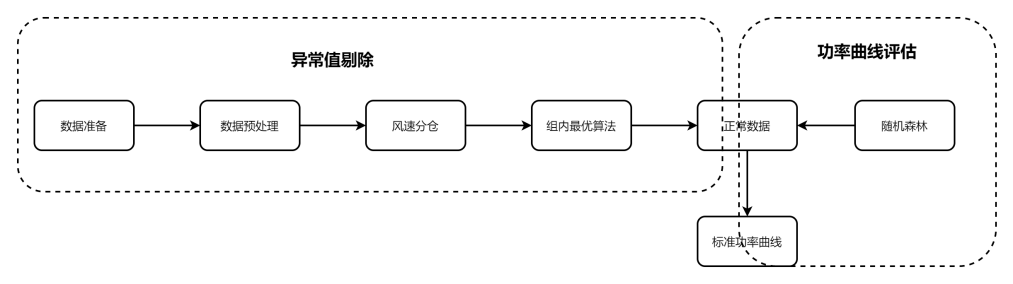 建模流程图
建模流程图
总结说明
采用组内方差最优算法对风机功率曲线进行异常值剔除,从下图中可看到严重偏离正常数据的异常值都能较好地挑出,其中绿色为异常值,蓝色为正常值。
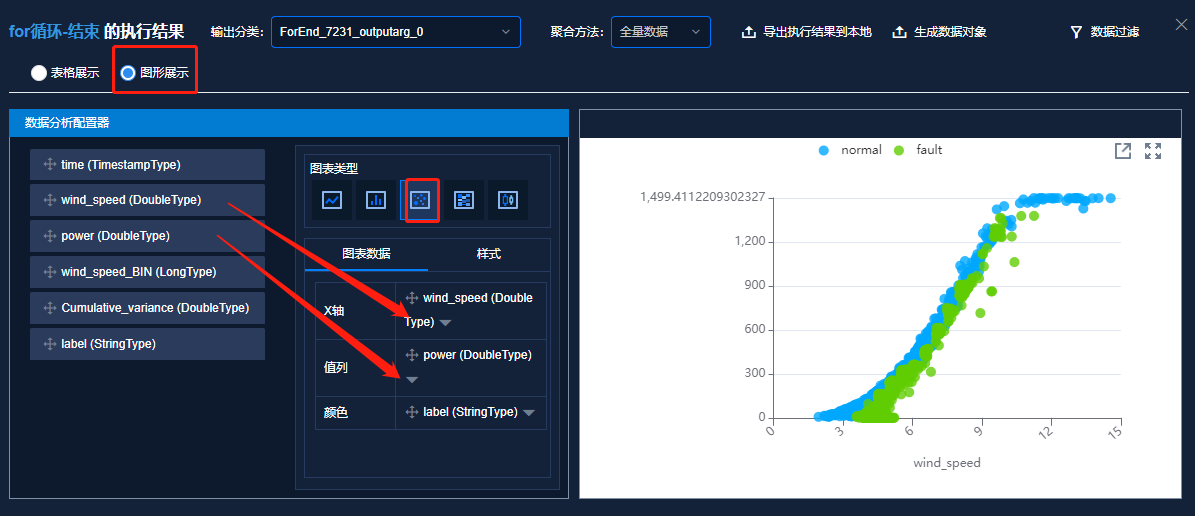 功率曲线散点图
功率曲线散点图
用随机森林算法对筛选出的正常数据构造模型,最终得到标准功率曲线如下图所示,在额定风速区间部分功率取值存在异常,可能是该风速区间内的样本量较少,导致预测值异常。
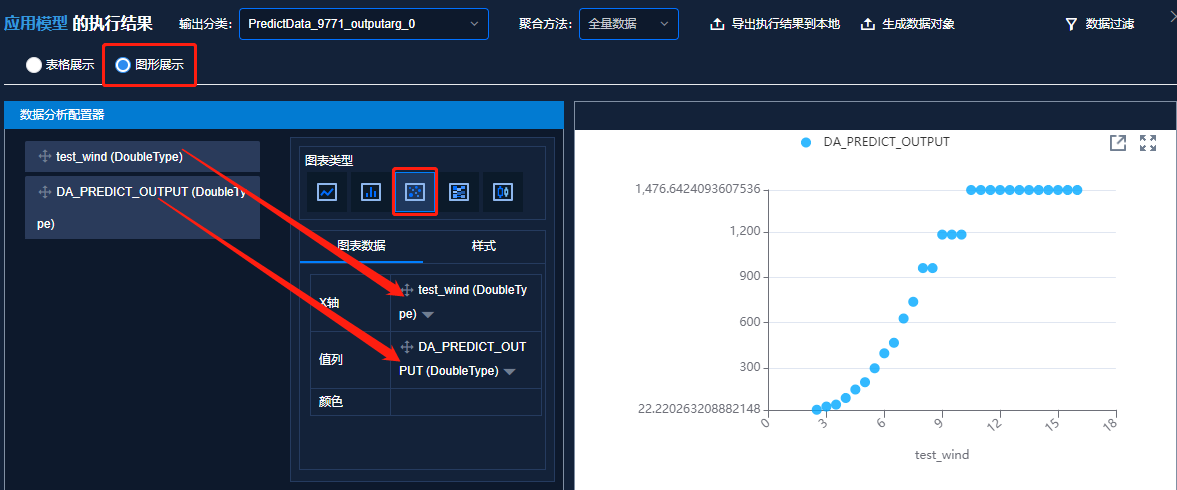 大风速段混淆矩阵
大风速段混淆矩阵
该模型能够最大限度的清理功率曲线中异常数据,以便拟合实际功率曲线用于功率预测和发电量评估。